
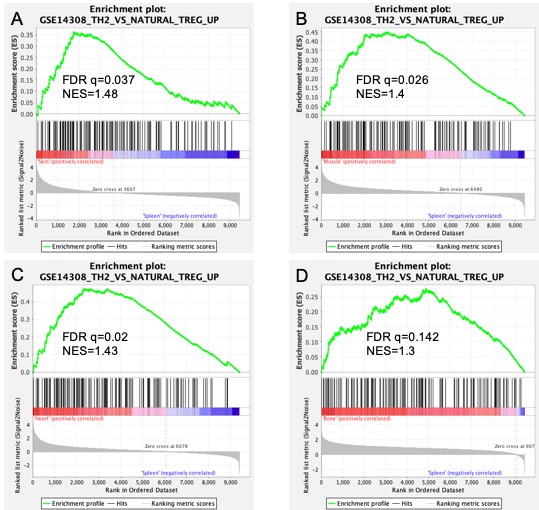
Hi, I am just starting to learn about GSEA analysis and I have conducted some analysis with four datasets so far. I have given below the gene set enrichment results of 4 datasets for the gene set (TH2 vs Natural Treg). Looking at the top half of the plots, my interpretation is that they are all enriched significantly. I have added in the FDR q vales and Normalised Enrichment Scores (NES) for each of them. However, I am a bit confused with the result in the bottom half of the plot. I am trying to understand what exactly does the "zero cross" mean? I have 4 I have read the user guide here (https://www.gsea-msigdb.org/gsea/doc/GSEAUserGuideFrame.html) and don't really find an answer to clarify this up for me. I specifically want to understand what is the significance or meaning of the differences in all these plots with respect to this "zero cross" value. Does it change any interpretation?, And what can one infer from it? For example, why is the zero cross for plot D at 907, and that of plot C at 6078 - what does this actually mean? Any guidance or help would be really appreciated, thank you!

Thank you so much for your response, I will keep in mind regarding making posts about Bioconductor packages! :)