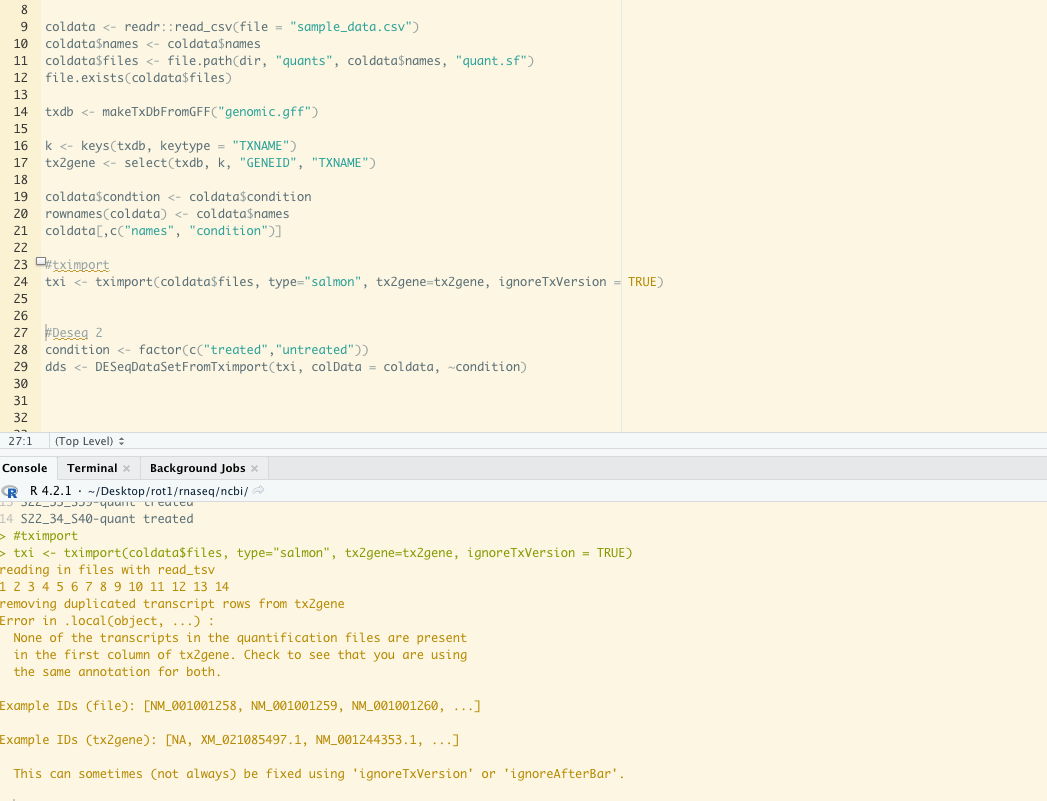
I am attempting to create a txdb and tx2gene for Sus scrofa transcipts.
I am struggling map my salmon transcript quant.sf files to my genome. I am using the transcript file from https://www.ncbi.nlm.nih.gov/data-hub/genome/GCF_000003025.6/, and tried to create a TxDb from the genomic sequence fast file, GFF3 and GTF. My IDs never seem to match and I am unsure how to fix this as I am pulling both files from the same site. I have also tried using the TxDb UCSC susScr11 ref genome but I get the same non-matching IDs.
Code should be placed in three backticks as shown below
# include your problematic code here with any corresponding output
# please also include the results of running the following in an R session
sessionInfo( )
My go-to in this situation is to get the transcripts from one of the quant.sf files and then map those using the TxDb. An example using an EnsDb from AnnotationHub looks like this
## get one file
tx2gene <- read.table(paste0("../data/aligned/", samps$Sample[1], "/quant.sf"), header = TRUE)
## get an EnsDb
hub <- AnnotationHub()
ensdb <- hub[["AH95744"]]
## generate the tx2gene using the transcript IDs
tx2gene <- select(ensdb, gsub("\\.[0-9]+$", "", tx2gene[,1]), "GENEID", "TXNAME")[,1:2]
You could do something similar, substituting in the TxDb you generated.